

MapReduce下的Flow分析
MapReduce计算框架下,任何数据都可以被看做是一对键值的组合。Map函数和Reduce函数是Map-Reduce的两大组成部分。Map函数用来对原始数据进行过滤,然后产生中间结果(也是键-值的形式)该中间结果作为Reduce函数的输入。之后,Hadoop会把具有相同键的值归为一个列表,然后再遍历列表进行数据的统计。Reduce过后,通常中间数据集都会缩小,因为Reduce过程中仅提取了该部分的有效信息。为了能使用MapReduce框架进行不同流字段的分析,应当设计自己Map和Reduce函数,如果要做某时间段的流量检测,那么Map函数要设计成带有可以提取某时间段所有流量的功能。如果我们要查看是否有潜在的DDos攻击,那么Map函数被设计成可以提取知名端口字段,其他的功能与此类似。
图2详细地介绍了统计某时间段流量的MapRed-uce的工作流程。图中有一个上文没有提到combiner的过程,该过程主要用于再从节点进行部分归并,以提高程序的运行效率。
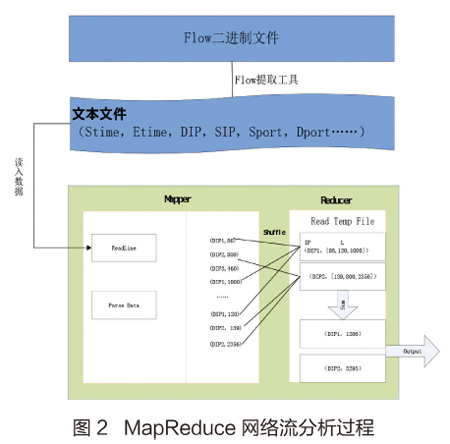
1.输入文件
首先,我们把提取的原始NetFlow字段利用SILK自带的工具rwfilter解析成Hadoop可以读出的数据字段,即文本字段。接着把这些解析出来的字段由Hadoop客户端上传到HDFS中,由于解析出来的文本字段远远大于原来的二进制形式的文件,所以需要把这部分输入规模变小一些。SILK本身并不提供解析二进制文件的接口,所以采取了把源数据进行压缩的方法,采取的压缩格式最好是能支持Hadoop的LZO,通过实验也证明了这种压缩方式确实有最好效率。
2.Mapper
Mapper首先读入存在在HDFS中的文件作为自己的输入,它的读入以行为单位。然后再用文本处理工具对这些行字段进行提取,提取的字段和要进行的操作有关。以统计某时段的某IP的流入流量为例,Mapper输入中会有IP、端口、协议、时间戳等字段。由于是进行某时间段流量的统计,我们把该时间段内的IP字段提取出来作为键,把该时间段内的流量提取出来作为值,这样就构成了一个Mapper。
3.Reducer
Reducer把Mapper的输出作为输入,同样以统计某IP地址某时间段流入流量为例。Mapper中得到了IP-Bytes键值对,Reducer中把相同的键所对应的值归并在一个列表L中这样,键值对就变成(IP,L),这样就可以遍历L并把所有的流量相加,就得到了我们想要的结果。
实验及结果对比
为了进行实验,我们搭建了1个主节点以及4个从节点的Hadoop-2.4.1版本的集群,集群的每个从节点带有2.83GHz的12核CPU,内存大小为48G,硬盘大小为40TB,集群的主节点带有一个12核2.83GHz的CPU和64G内存。为了提高效率,主从节点均在同一个机架上,连在同一个交换机上。SILK的对比试验则是在单节点上进行,配置相同。
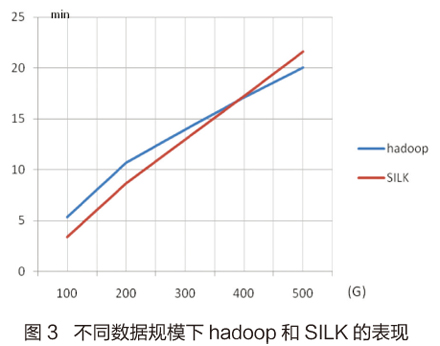
可以看到当数据量不大时,SILK往往具有更快的速度,这是因为Hadoop在进行计算前,要做一些集群间的通信及初始化工作,在小数据集上并不占优势。然而当我们把实验数据逐渐加大时,发现Hadoop会在某个点超越SILK的分析速度,当数据集再逐渐扩大时,Hadoop的优势变得更加明显,如图3所示。
本文主要展示了如何利用Hadoop和MapReduce框架进行大规模的网络流的分析的方法,并列举了几个利用这种方法进行实际分析的实例以及和传统方法进行网络流分析的对比。实践中,该方法在大量数据的情况下相比于传统的流分析工具具有更高的效率。另外它在可靠性、可扩展性方面也有着突出的表现,随着Hadoop更高版本的推出,现在的单点故障问题以及分布式系统安全方面也有了显著的提升,使得该方法的应用更成为了可能。
(作者单位:1为华中科技大学计算机学院,2为华中科技大学网络与计算中心)

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
基于云计算的推荐系统的研究与实现2012/05/07
基于虚拟机的云计算管理平台2011/04/28
虚拟技术降低分布式存储系统部署成本2012/04/28




投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com