

文/孔祥玉1张峻飞1凃浩2
在网络流量的分析中,基于流的分析被大多数ISP所采用,分析系统一般部署在一台高配置的服务器中。如由CERT网络势态感知团队(CERT-NetSA)开发的用于大规模网络安全分析的网络交互分析工具集SILK(the System for Internet-Level Knowledge),支持有效的收集、存储和分析网络流数据,SILK可以高效地查询历史大流量数据集,能用于分析大的企业或者中型ISP的骨干或边界网络流量。然而,随着互联网带宽的日益增加,单台系统会受到硬件等因素的限制使计算速度变得很缓慢,而且数据存放在单个服务器时的风险往往也很大,需要考虑使用分布式的方法。而分布式计算平台Hadoop以及依托在Hadoop平台下的MapReduce框架为解决这类问题提供了良好的支撑。Hadoop是Apache的一个子项目主要由分布式文件系HDFS计算框架和资源管理器YARN组成,其中MapReduce是当中最著名的计算框架,也是大规模分析网络流量的基础。
Hadoop搭建的网络流量分析系统比之传统的分析手段有着以下的优点:1.更节省成本。只用少量的廉价机器就可以搭建起一个基于Hadoop的分布式计算平台;2.更具扩展性。使用分布式计算框架,每个节点都参与运算,计算效率随着节点数的增加线性增长;3.更加可靠。分布式数据系统HDFS保证了备份数据的数量均匀分布在集群内部的各个节点上,数据更不易因机器的故障而丢失。本文基于Hadoop设计实现了适用于大规模网络流量的分析系统,使用了四个节点构成的分析集群,用来和一个单点SILK的数据流分析工具进行对比,结果表明该方法在大量数据的情况下相比于传统的流分析工具具有更好的效率、可靠性及可扩展性。
网络流分析
一条流由一个源主机与一个目的主机间的单方向传输的网络数据包组成,其中源和目的主机由各自的IP地址和端口号来标识。更明确的定义是,一条流由源IP地址、目的IP地址、源端口、目的端口、时间戳、服务类型、入逻辑接口标识符等关键字唯一标识。
在过去的数十年间,有很多技术和工具被广泛地应用到网络流量的分析当中。Tcpdump是最常见的一种网络流分析工具,Wireshark则提供了用户友好的界面,以其简单易用性著称。CoralReef和Snort的相继出现为实时分析网络流量也做出了很大的贡献。随后又出现了如SILK等网络流分析工具。这些网络流分析工具在少量的数据下完全可以胜任网络流分析的工作。然而随着近几年来数据爆炸式的增长,传统的基于单点的网络流量分析的方法变得越来越不能满足需求。
Hadoop中的MapReduce计算框架以前主要被应用于大规模的网络文本分析、数据挖掘以及日志分析当中。在本次工作中,我们把MapReduce创新性的应用在了网络流分析当中,这样就可以使相应的网络流的统计不在拘泥于一个节点上,突破了单点网络流统计的局限性。同时使得网络流分析具有了更高的可扩展性,每当集群遇到计算瓶颈时,我们只需加入更多的节点,就可以使计算速度提升,而不是花费大量的金钱去购买更高配置的机器。
Hadoop网络流量分析
NetFlow产生大量的数据,但大多时候我们只需要这些数据的统计结果。用普通的串行方法可以在少量的数据集上进行统计,并且达到很理想的效果,但是一旦数据超过一定量级,便不能有效地进行处理,这时一些基于分布式的并行计算框架就有了用武之地。为了实现并行计算,已经有很多组织机构提出了多种方法,其中以Google提出的MapReduce框架最为著名。该框架已被广泛应用于文本搜索,海量数据挖掘等场合。
概述
图1展示了我们进行流分析时的机器拓扑结构。其中Hadoop云平台提供了分布式文件系统HDFS和云计算功能。
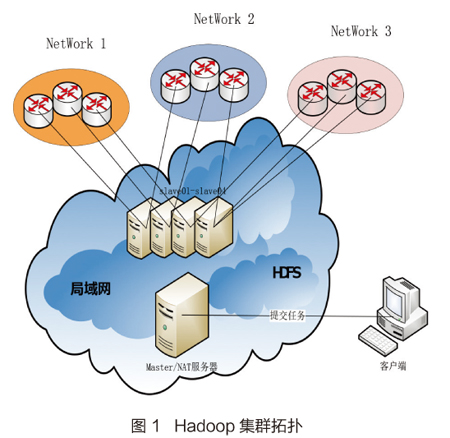
首先从各个数据源中提取数据,然后把各个数据源数据解析出来的可读数据上传云平台上。云平台的计算由一个主节点组织,若干从节点协同。主节点用来存储元数据、分配资源和任务调度。我们可以对其进行相应的系数配置如缓冲区大小、数据分片大小、处理线程的多少等因素,以更好地达到实验效果。从节点则接受主节点的调度,主要参与运算,同时也会定时反馈自己所在节点的状况。每个从节点上会根据HDFS的配置有若干份,在进行分布式计算时,从节点计算时通过Hadoop自带的RPC协议来进行通信。具体的计算过程则是由MapReduce框架完成。

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
基于云计算的推荐系统的研究与实现2012/05/07
基于虚拟机的云计算管理平台2011/04/28
虚拟技术降低分布式存储系统部署成本2012/04/28




投稿、转载或合作,请联系:eduinfo#cernet.com (请将#替换为@)
版权所有:中国教育和科研计算机网网络中心 CERNIC,CERNET
京ICP备15006448号-16 京网文[2017]10376-1180号  京公网安备 11040202430174号
京公网安备 11040202430174号
![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}
关于假冒中国教育网的声明 | 有任何问题与建议请联络:Webmaster@cernet.com