

我们已经迈入了一个高度智能化的时代。近年来,ChatGPT等人工智能(Artificial Intelligence,AI)应用不断带来惊喜。面对各种问题和需求,人工智能之所以能够表现出“智能”,一个很重要的原因是其背后有着强大的计算资源作为础支持。基于这些计算资源,可以训练出高质量的人工智能模型,帮助人们解决问题。因此,如何充分运用好超大规模的计算资源,就成了人工智能时代亟需解决的重要基础问题。
近年来,来自北京大学计算机学院、人工智能研究院的青年学者,关注面向人工智能的基础系统软件这一领域,组成研究团队,开展联合研究,连续发表高质量学术论文并多次获奖,取得了重要的学术研究进展,而且成果在工业界开展了大规模实践,产生了积极的产业影响。
01 实现系统软件“根”的突破
当前以深度学习为代表的人工智能,本质上是一种数据驱动的智能,首先要从大量的数据中“学习”出一些规则生成一个模型(称之为模型训练),然后要运用这些规则来解决问题(称之为模型推理)。如果做个比喻,可以粗略地把模型训练过程当作“看例题”,把推理过程当作“写作业”。人工智能可以做到在边看例题的同时边写作业。不过,用多少精力看例题,用多少精力写作业,以及这些精力如何分配得合理、高效和经济,就不再是人工智能自身能够解决的问题,而必须要依赖底层的系统软件来调度算力资源为其赋能和提供支撑。
在计算机领域,系统软件处于“承上启下”的位置:向下要管理各类硬件,向上要支持各类的应用,扮演“顶天立地”的角色。在人工智能时代,系统软件的挑战更大,需要“全栈式”的研究思维,不仅需要掌握系统软件自身的知识和技能,还需要了解硬件体系结构和人工智能的模型和算法,甚至需要一些经济学和伦理学的知识,因此开展交叉融合研究尤为必要和重要。
在过去几年里,来自计算机学院软件研究所的刘譞哲、金鑫、李锭,联合网络与高能效计算研究所的许辰人和人工智能研究院智能系统软件研究中心的马郓,组成了一支以青年学者为主的研究团队,带领和组织20余名博士研究生,坚持面向系统软件的领域前沿突破核心技术。
团队在SOSP、OSDI、ASPLOS、SIGCOMM、NSDI、WWW等顶级学术会议发表多篇论文,获得了中国首个WWW大会最佳论文奖、IEEE云计算技术创新奖,以及教育部青年科学奖、阿里-青橙奖等多个学术荣誉。同时,团队非常注重和工业界需求实践结合,成果在抖音、阿里等工业界大规模环境部署,取得了多项突破,努力从底层筑牢人工智能发展的根基,服务国家经济社会建设需求。
团队以“巴斯德象限”来诠释科研的选题和定位。相对于以基础原理探索为导向的“波尔象限”和以应用为导向的“爱迪生象限”,瞄准“巴斯德象限”意味着从事既受好奇心驱动、又面向应用的基础研究,这与系统软件的“基座”属性及其在国家重大需求中的重要基础地位有关,也使得团队的研究在“前沿导向的探索性基础研究”和“战略导向的体系化基础研究”之间取得平衡。
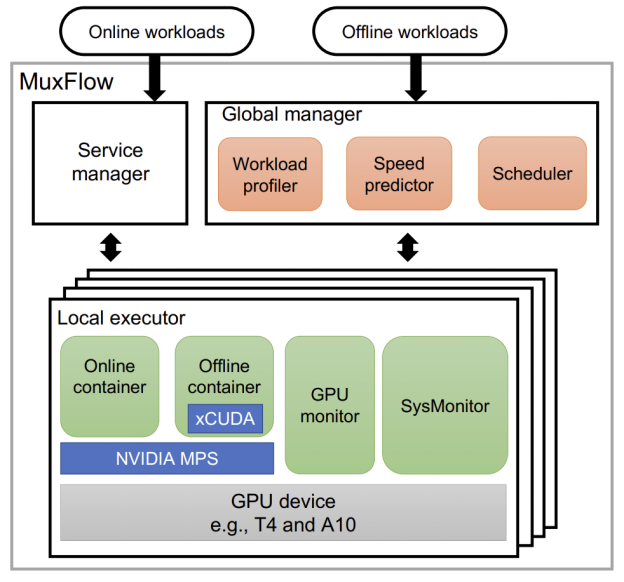
在实践中,云计算平台上通常要同时支持训练和推理两类负载,每类负载往往都包含着大量的任务,而且日益增长的规模度和复杂性导致GPU共享的实现难度极大。针对这一问题,团队和抖音集团合作研发了具有通用性的动态GPU算力分配系统MuxFlow并在抖音集团进行了大规模部署,GPU集群的资源利用率得到了大幅度的提升,节省了大量的运营成本。
当前流行的大模型推理服务系统使用的是FCFS(先来先服务)的处理方式,容易受到头阻塞的影响从而导致较长的任务完成时间,团队开发出了一种支持大模型任务的推理加速系统FastServe。FastServe采用了一种新颖的跳跃链接多级反馈队列调度器,调度器根据用户请求的输入长度信息,为每个到达的任务分配适当的初始队列,优先级更高的队列则会被跳过以减少降级;同时,为了解决推理过程中的大量内存占有问题,团队设计了一种高效的GPU内存管理机制,可以有效提高ChatGPT这类大模型推理任务的响应速度。

模型训练任务一般是离线进行,但开发者往往希望任务能够在预期截止时间前完成,此前的机器学习系统同时并行处理多个任务,难以感知和处理每个用户的预期截止时间,也无法保障每个训练任务的服务质量。团队设计实现了弹性分布式深度学习系统ElasticFlow,在给定的预期截止时间内,ElasticFlow可以将训练任务的完成数量提升1.46-7.65倍。这个系统特别适合科研院所的模型训练需求,目前正在北京大学计算中心部署测试,未来将有望服务于全校师生。
此外,团队也一直在思考如何为更普惠便捷的智能服务提供系统软件支撑。在保护用户数据安全的前提下,团队甚至成功地将“模型训练”任务放在手机等轻量级设备的终端上,通过对CPU、GPU和数字信号处理器DSP等端侧异构计算资源的混合调度,以及突破“内存墙”的限制,将训练速度提升了5.5倍,能耗降低了10.9倍。该成果在国家电网和Kika Keyboard上线,已经服务了全球上百个国家的用户。
02 努力打造软件研究的“中国名片”
能在短短数年内实现基础设施系统软件的诸多突破,与北京大学软件团队长期以来的技术积累和团队的科研传统是分不开的。不同于计算机应用的日新月异,作为“底层基座”的系统软件的更迭,更像是长期围绕着一个主线的变奏。因此,在一个又一个信息化浪潮中,北京大学软件团队始终能站稳脚跟,但这无疑也考验着他们的功底扎实度和耐心度,没有相应的实践和长期的积累,要做好系统软件几乎是不可能的。
上世纪70年代,杨芙清院士建立了北京大学软件研究团队。近半个世纪以来,以杨芙清院士、梅宏院士作为学术带头人,北京大学软件研究团队长期主动对接软件领域的重大问题和国家重大需求,承接重大任务,有组织地开展团队技术攻关,完成了我国软件发展历史上的多个首次突破。在系统软件领域,北大软件团队在云计算、大数据领域的基础设施系统软件方面已形成了重要的积累,获得了国家技术发明一等奖/二等奖、教育部科技进步一等奖等。从云计算、大数据处理到机器学习,虽然运行环境和任务类型在发生变化,但作为底层基座的系统软件的任务,始终是追求更好地发挥出计算资源的能力,更好地服务上层的应用需求,这也是系统软件研究者不懈努力的命题。系统软件研究影响力不仅体现在高质量的论文发表,也体现在能否有被人熟知和广泛使用的软件。以有世界影响力的前沿成果服务国家,这也是团队始终坚守的研究目标。
03 培养引领未来的卓越软件人才
培养出一流的系统软件人才,这是北大软件团队一直坚持的核心要义。科研脉络的前后承续,要求团队既能晓通变之理,也要有核心的凝聚力。事实上,软件学科的偏“工程”属性,就决定了科研过程的有组织性非常关键。个人的兴趣、聪明才智和努力与团队成员间的密切合作,是带动科研工作腾霄破空的两翼,而教育的薪火、人才的培养、科技的探寻,也在团队的协力共进中融为一体。
善于发现学生的优点,尊重学生的个体差异,是团队中的共识。在学生培养上,团队已经形成了一个成熟的模式。学生加入后,可以先跟着一个既有项目做实验、分析数据、调试系统等等,熟悉了科研的基本操作和流程后,就可以和老师商量着做一个自己的题目,有意思的是,这个过程中会不断受到来自老师的质疑和辩难,以保证选题的创新性和合理性,这对师生双方来说都是富有挑战性的环节。因此,团队鼓励学生和老师讨论、辩论甚至争论,真理越辩越明,这是北大人的特质,也是团队坚持的文化。
系统软件的市场需求大,但相应地,技术门槛高,研究周期长,团队的老师们深谙此点,也给予学生充足的耐心,每个学生培养起来都需要一定的周期,前期的稳扎稳打,正是为了后期学生们敢于在自己的项目中放手一搏。
团队建设过程中,还很好地体现了北大学科交叉融合的特点——加入团队的学生不都是计算机学科出身,还有来自化学、物理、医学等其他学科的学生。系统软件不仅是一门技术,也是一门艺术,它很多地方体现了哲学性、人文性的思考,而北大的多元学科所赋予的思维上的滋养,也是北大系统软件能在国内乃至国际独树一帜的重要因素。
过去几年里,多元自由的氛围孕育着青年学生的科研主体性,培养出了优秀的学生。例如,1名学生获得了中国计算机学会优秀博士论文和北京市优秀博士论文,1名学生获得了ACM SIGMOBILE中国优秀博士论文奖,2人入选北京市科技新星,2名学生获得北京大学学生最高荣誉“五四奖章”,2人入选“微软学者”(每年全球仅10-12人),1人当选北京大学“学生年度人物”。此外,2名本科生在网络系统领域顶级会议SIGCOMM和NSDI发表独立一作论文,这在中国大陆均为首次。
让学生难以忘怀的经历里,除了科研,还有充满仪式感和欢乐气息的共同记忆:“我们每周三都会跟老师一块儿打球,学生们一队,老师们一队,老师们都太厉害了!”,“我们会自己组织新年晚会,老师和学生们一同表演节目,大家都好有才”,“我们每个月都会举办生日会,为过生日的老师和同学集体庆生”。
这个充满创造活力的团队,也是一个共同奋进的温暖大家庭,他们将为中国软件研究的自立自强不断贡献力量。
从这里,正在走出一支学术和行业的生力军,为人工智能时代的系统软件基座发出北大的声音。

特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。












 京公网安备 11040202430174号
京公网安备 11040202430174号![京网文[2017]10376-1180号](/images/indexnew/www1024.jpg){kind=link}