
编辑点评:一个成功的智能问答系统的设计,关键在于知识库构建的全面性和合理性,以及信息检索速度和质量的均衡性。本文针对校园环境的知识问答进行了专门设计,重点研究和实现了对校园知识的分类和针对不同类型知识所采用的匹配和检索方法。
1.引言
智能问答系统作为一种人性化和智能化信息服务手段,近年来被大量广泛地研究。它以一问一答形式,精确定位用户的提问知识,通过与用户进行交互,为用户提供个性化的信息服务,满足用户获取知识,查询信息的需要,因此能从很大程度上替代传统的人工咨询等解答问题的方式。
问答系统实现的核心目标是针对给定的一个问题,能够快速得到简短、精确的答案。根据不同系统所提供答案的知识领域,问答系统可分为开放领域问答系统与限定领域问答系统。开放领域问答系统的知识源一般非常丰富,为问题的答案提供了较为充分的知识准备,但也带来了难以给出用户精准答案的弱点;而限定领域的问答系统因知识范围边界较为清晰,可以根据实际情况设立领域模型,从而较好地在领域内定位答案更好地为用户提供精准答案。
本文经过分析高校校园这一应用领域特点,研究设计了一种基于多层策略的校园智能问答系统,可以帮助高校建立统一的信息获取平台,自动解答师生员工用自然语言提出的关于教学、科研、人事、网络服务、后勤服务等方面遇到的问题,为学校提供良好的信息化服务途径。
2.相关研究分析
问答系统依据处理的数据格式,主要可归为两类[1]:“基于问题答案对的问答系统”和“基于自由文本检索的问答系统”。无论哪一类,为达到快速准确获取答案的目标,都需要完成问题分析、信息检索和答案抽取3个核心功能。
2.1 问题分析
问题分析主要用于分析和理解问题,需要完成以下三部分工作:问题分类、关键词提取、关键词扩展等,对于中文问答系统,问题分类之前还需要先进行问题分词和词性标注等预处理。
(1)问题分类:不同类型的问句有不同的处理规则,因此需要先对问题分类。最简单方法是基于模式匹配的方法[2],即对每一种问题类型建立一个问题模式集合,通过问句匹配问题模式来确定问句的问题类型。基于统计的机器学习方法[3]性能更好,这类方法首先定义一个问题的特征集合,然后在训练数据上得到一个分类器,继而对新问句进行分类,典型算法有:基于支持向量机的汉语问句分类算法、基于KNN的汉语问句分类算法、基于朴素贝叶斯的汉语问句分类算法[4]等。
(2)关键词提取:问答系统需要从查询问句中提取出对信息检索有用的关键字。关键词一般由名词、动词、形容词、限定性副词等组成。最简单的关键词提取方法是删除停用词(如,语气助词、结构助词等),其余词作为关键词。也有提取问句焦点信息作为关键词的[5],例如:将问句解析为数量块、时间块、处所块、实体块、属性值块、事件块、角色块等7类语义块;将问句解析为主语、谓语、宾语等组成成分,主语、谓语、宾语分别代表一个信息焦点。
(3)关键词扩展:问答系统检索到的答案句子中的词常常不是原来问题的关键词,而是关键词的同义词,因此为了提高信息检索的召回率,需对关键词进行扩展。最常见的关键词扩展的方法是使用同义词词典,中文同义词词典有Hownet、同义词词林等。
问题分析后,得到的结果是问句形式化及形式化扩展后的关键词序列。
2.2 信息检索
信息检索的主要目的是缩小答案的范围,提高下一步答案抽取的效率和精度。
对于“基于问题答案对的问答系统”,信息检索的任务是找到和查询问句类似的问题,返回答案或者相似问题列表。用到的方法是问句相似度计算算法。目前中文相似度计算方法主要有四类:基于关键词信息的方法、基于语义信息的方法、基于句法结构信息的方法以及基于多重信息的方法。
对于“基于自由文本检索的问答系统”,信息检索的任务是用问题分析时提取出的关键字到文档库中查找,返回与问题最相关的文档。一般分为两个步骤:(1)文档检索:检索出可能包含答案的文档,最关键的问题是对文档权重的确定和对文档进行排序,文档的权重计算可参考问句相似度计算算法;(2)段落检索:从文档检索得到候选文档中抽取出可能包含答案的段落。较好的段落检索算法有三个:MultiText算法、IBM的算法和SiteQ算法,这三个算法都使用了IDF值的总和,都考虑了邻近关键词之间距离的因素,但都没有考虑关键词在问句中的先后顺序,都没有考虑语法和语义信息。
2.3 答案抽取
答案抽取的主要目的是从信息检索获取的段落集合中进一步定位,获取更加精确的正确答案。在大多数情况下是返回句子作为答案,答案抽取步骤如下:(1)把检索出来的文档分成句子;(2)按照一定的算法,计算每个句子的权重;(3)对句子按照权重进行排序;(4)根据问题的类型对候选答案重新排序;对有些问题,简短的句子可能难以说清,这就需要用到多文档自动文摘技术,把信息检索模块检索出来的相关文档做成文摘作为答案返回给用户。
3.校园领域模型的分析与建立
3.1 校园知识类型
建立高校校园问答系统,可根据校园领域中的信息来源和表现形式将其知识类型分为3类:
(1)服务型知识:如教室空闲状况、个人成绩查询等;这类知识来源固定,一般由对应的管理部门发布或者存在于学校的管理系统中;在表现形式上,这类知识是格式固定的结构化数据,如:一条空闲教室状况知识由时间、教学楼、教室名称、空闲时段组成;
(2)常见问题型知识:如学校各部门办事流程、规章制度、服务指南;这类知识一般来源于校园各个网站上的FAQ列表,当然也有相当一部分是蕴藏在管理人员的脑海里的“隐性知识”;表现形式属于典型的“一问一答”;
(3)文本检索型知识:所有校园网站上的网页蕴含的内容都可以归类于这类知识,因此知识来源非常广泛;在表现形式上属于大段的自然语言文本,从中获取答案必须进行信息检索和答案抽取;
服务型知识相对来说比较稳定,可枚举;常见问题型知识可通过提取校园各单位的部门网站上的FAQ获取,当然通过发掘和整理蕴藏在管理人员的脑海里的“隐性知识”,可以获得更多这类知识;文本检索型知识可通过爬虫程序从校园网中的网页中抓取。
通过对知识的分类,发现获取不同知识的途径和知识本身的表现形式都是不一样的,无论传统的基于问题答案对的问答系统,或者基于自由文本检索的问答系统,都不能完全适用于北京大学的实际情况。因此,应对不同类型的知识应该采取不同的策略来获取。
对于服务型知识,因其知识来源和表现形式都比较固定,并且都能通过数据接口等方式获取,故可将查询问句按其问题模式,转换为标准的服务接口,然后调用接口获取结构化的答案;对于常见问题型知识,可以借鉴“基于问题答案对的问答系统”的策略来获取问题答案;对于文本检索型知识,可以借鉴“基于自由文本检索的问答系统”的策略来获取问题答案;
3.2 模型结构
针对上述知识特点,我们设计了具有三级策略的问答系统模型,将提问者的问题逐级匹配查询答案:
第一级是“特定服务查询”,将查询问句转换成预设的服务接口,采用“基于模式匹配”的方法来完成查询问句与服务接口之间转换,一种问题模式对应一个服务接口实例,通过将查询问句与问题模式匹配来确定问句对应的服务接口;若查询到答案,则将结构化的数据返回用户;
第二级是建立常见问题库(FAQ)存储问题和答案对,对FAQ库的问题进行问题分类,同时将查询问句进行归类,再将查询问句与该类别下的所有问句进行相似匹配,当相似系数超过某个指定的阈值时则认为匹配成功,获取问题-答案对返回给用户;
第三级采用自由文本检索的方式,运用开源的全文检索引擎solr检索,对solr返回的按相关度排序的网页文档,使用答案抽取算法抽取相关度最高的段落或者短句返回给用户。
三级策略模型在设计实现上主要由“特定服务查询模块”、“常见问题查询模块”和“自由文本检索模块”三部构成。其结构如图1所示。
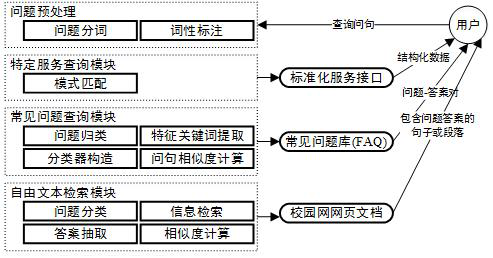
图1 三级策略模型

![京网文[2014]2106-306号](http://img.eol.cn/images/indexnew/www1024.jpg){kind=link}