
编辑点评:本文提出了一种适用于IPv6,提高路由器报文转发效率的一种IBFBP神经网络算法,将一个大的神经网络分解成多个小的神经网络使得每个神经网络学习的路有条目相应减少,从而提高了学习的效率。
0 引言
随着因特网的快速发展,IPv4地址日益紧张,虽然提出了CIDR无类域间路由,私有地址等解决方案,但终究是治标不治本,终究会消失殆尽,IP地址相关管理组织于2011年2月3日宣布分配完毕,一方面是地址资源数量的限制,另一方面是随着电子技术及网络技术的发展,计算机网络将进入人们的日常生活,可能身边的每一样东西都需要连入全球因特网。地址的不足严重地制约了中国及其他国家互联网的应用和发展。所以我们提出了IPv6,相比IPv4,IPv6采用了128位二进制数编址,具有巨大的地址空间[1-3]。再者路由器是构成因特网的骨架。它的处理速度是网络通信的主要瓶颈之一,随着互联网用户的大量增加,用户网络要求的提高,网络带宽越来越大,相应的路由有条目就越来越多,这就对路由器产生了巨大的挑战,提高路由器的硬件配置可以提高他的运行速度,但这不是长久之计,而且昂贵。所以一个好的算法也是提高路由器性能的关键。本文就提出了一种适用于IPv6,提高路由器报文转发效率的一种IBFBP神经网络算法,将一个大的神经网络分解成多个小的神经网络使得每个神经网络学习的路有条目相应减少,从而提高了学习的效率[4-6]。
1 问题描述
IPv6路由查找要求最长匹配的路由查找地址,相比精确匹配更为复杂。利用BF算法与BP神经网络相结合,通过BF算法将IPv6地址前缀进行分类产生不同的集合,每个集合对应一个BP神经网络,将多对一的问题转化成一对一的问题,能够快速查找路由[7,8]。但是标准的BF算法存在当插入的元素越多,错判在集合内的概率就会增大,容易产生误判,而误判率的大小将会影响搜索过滤的成本。本文对BF算法进行改进,使其减少误判率的发生,降低搜索过滤成本,从而提高IPv6路由查找效率[9]。
2 改进Bloom Filter算法
2.1 标准Bloom Filter算法
在哈希算法中存在一个冲突(碰撞)的问题,用同一个哈希函数得到的两个结果值有可能相同。为了减少冲突,应更多的引入哈希函数,如果通过其中的一个哈希值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的哈希函数告诉我们该元素在集合中时,才能确定该元素存在于集合中,这就是Bloom-Filter算法。
如图1所示,首先,Bloom Filter是一个m位的位数组,且全为0。同时,需要定义k个不同的hash函数,每一个hash函数都随机的将每一个输入元素映射到位数组中的一个位上。那么对于一个确定的输入,我们会得到个索引。
插入元素:经过k个hash函数的映射,我们会得到k个索引,我们把位数组中这k个位置全部置1(不管其中的位之前是0还是1)
查询元素:输入元素经过k个hash函数的映射会得到k个索引,如果位数组中这k个索引任意一处是0,那么就说明这个元素不在集合之中;如果元素处于集合之中,那么当插入元素的时候这k个位都是1。

图1 Bloom Filter工作过程
2.2 改进的Bloom Filter算法
在传统的Bloom Filter算法中:
1、存在误判,图一中,当插入x、y、z这三个元素之后,再来查询w,会发现w不在集合之中,而如果w经过三个hash函数计算得出的结果所得索引处的位全是1,那么Bloom Filter就会告诉你,w在集合之中,实际上这里是误报,w并不在集合之中。
2、标准的Bloom Filter算法,只支持插入和查找。当表达的集合是静态集合时,标准的Bloom Filter可以正常工作,但是如果要表达的集合是变动的,标准Bloom Filter的弊端就显现出来了,无法从Bloom Filter集合中删除一个元素。因为该元素对应的位会牵动到其他的元素。
对于标准的Bloom Filter算法存在的不足,提出改进的Bloom Filter算法,IBF是在标准的BF算法的基础上,以哈希函数关键字的特征建立一个标志库且以关键字的最小值作为标志来区分,在搜索过程中只需将查询数与标志的位置一起做查询,来判别测试值是否存在,不仅能达到过滤的基本要求并且能大幅减少通过搜索过滤器后需比对的关键字的数量,降低整个过滤器搜索所需要花费的搜索成本,让搜索过滤器有更好的性能。从而提高了效率。空间的节省和查询的高效是通过一定的错误率来换取的IBF虽然不能完全消除误判,但是相比BF大大降低了误判的发生。对于标准BF不能进行删除操作IBF做出的改进是将位数组用counter数组来代替,在插入元素时给对应的k个counter的值分别加1,删除元素时给对应的k个counter的值分别减1。
如图2,假设有一集合S={n1,n2,n3,n4,n5,n }有六个元素,h1,h2,h3(k=3)三个哈希函数,用LB来代表建立的标志库,用来存放标志。
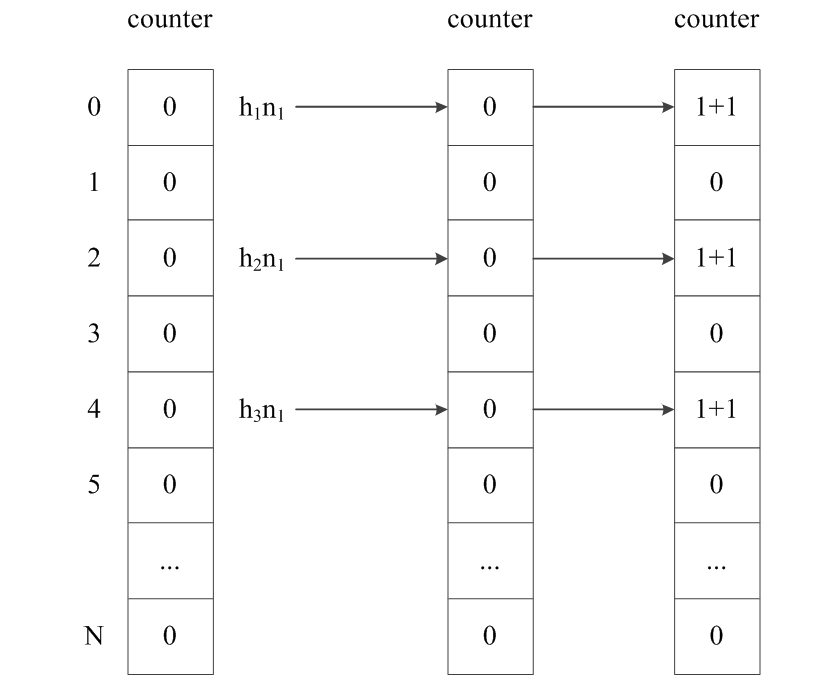
图2 counter数组
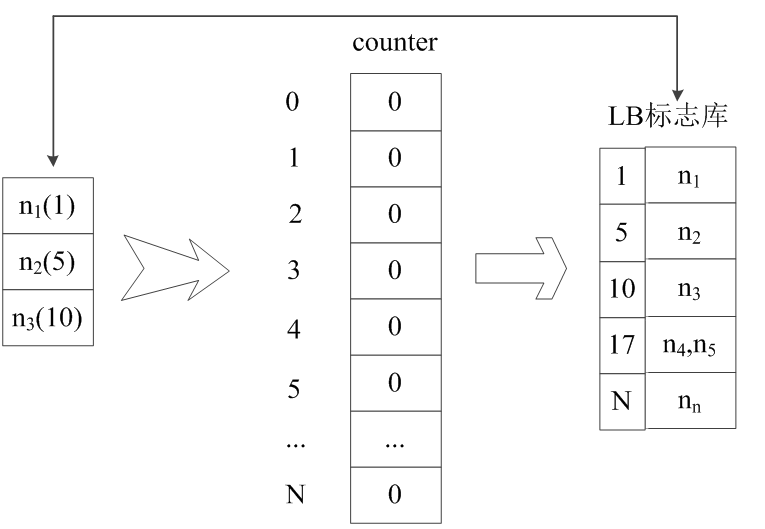
图3 LB标志库

![京网文[2014]2106-306号](http://img.eol.cn/images/indexnew/www1024.jpg){kind=link}